一、整体上看测试
- 代码是一种负债,而不是一种资产。人们通常认为测试越多越好,事实并非如此,引入的代码越多,软件中潜在错误的表面积就越大,项目的维护成本就越高。用尽可能少的代码解决问题总是更好。
- 测试也是代码。应该将它们视为旨在解决特定问题的代码库的一部分:确保应用程序的正确性。与任何其他代码一样,单元测试也容易出现错误并需要维护。
- 测试覆盖率
- 代码覆盖率:测试中执行的代码行数/生产中执行的代码行数
- 分支覆盖率:测试中所有执行到的分支数/生产中所有可能执行到的分支数
- 测试覆盖率是一个很好的负指标,但却是一个糟糕的正指标。即:覆盖率低代表你的代码质量可能非常差。但覆盖率高并不能保证你的代码质量高,反而会带来一些不必要的麻烦比如维护成本、对不必要的测试验证投入较高的时间、新版本可能永远延期发布等
- 总之测试覆盖率是一个指标而不是一个目标
- 一个好的测试套件具有以下属性:
- 它被集成到开发周期中。
- 它只针对代码库中最重要的部分。
- 它以最低的维护成本提供最大的价值。
二、单元测试的定义
-
三个重要属性
- 验证一小段代码
- 执行快
- 具有隔离性
-
对于第三个属性的理解差异催生出两个流派
- 经典派:主张将其视为单元测试的本身与彼此的隔离
- 伦敦派:主张将其视为被测系统与其合作者(依赖项)的隔离
-
测试依赖
- 共享依赖:如数据库、文件系统
- 私有依赖:如其他的类
- 可变依赖:如数据库、行为不确定的类
- 不可变依赖:如枚举类、数值
- 进程外依赖:如数据库。注意共享依赖通常是进程外依赖,如果共享依赖是进程内的那么为了隔离性和并发测试你可以为每个测试单独创建一个实例,这时就转为了私有依赖
-
经典派与伦敦派对比
隔离目标 单元定义 使用测试替身的范围 伦敦派 一个单元 通常是一个类 除了不可变的依赖项 经典派 一个测试 一个类或一组类,通常是指一个行为 只对共享依赖 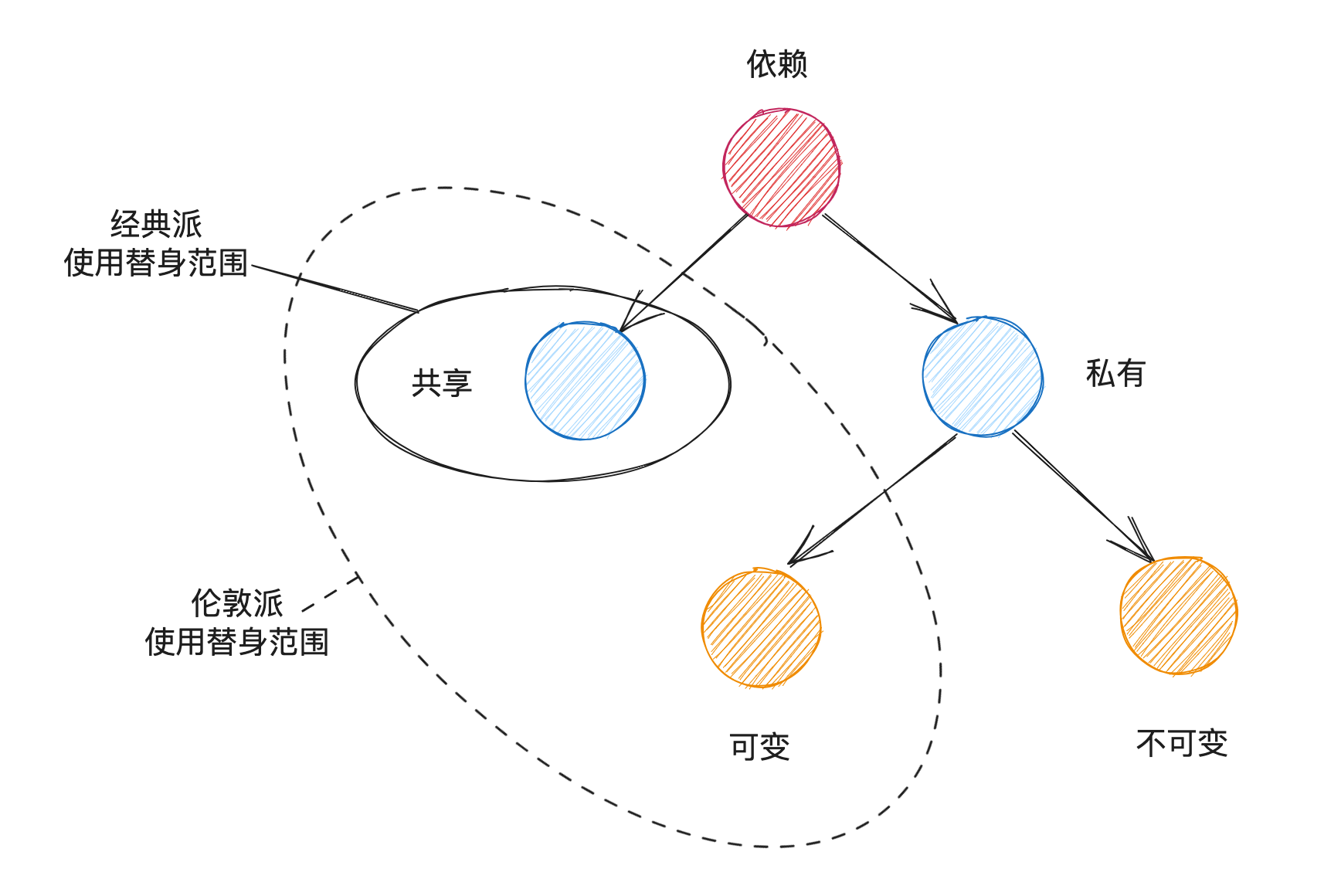
-
作者倾向于经典派,因为伦敦派会导致脆弱性测试,后面有解释。
三、剖析单元测试
-
一个测试方法的构成(AAA 模式)
public void test_add() { // Arrange 编排 int a = 9; int b = 10; int sum = 19; Calculator sut = new Calculator(); // Act 行动 int addSum = sut.add(a, b); // Assert 断言 assert sum == addSum; } -
避免一个测试方法中使用多个 arrange、act 和 assert 部分 一个测试中出现多个 AAA 意味着你在一个测试中验证了多个行为,这通常是集成测试的职责
-
避免使用
if语句if语句也表示你在一个测试中验证了太多的东西,与多个 AAA 不同的是无论单元测试还是集成测试都不应出现分支,它只会使测试更加难以阅读和理解,从而增加维护成本 -
AAA 每个部分的行数
- Arrange 部分通常是行数较多的,但过于多时(远超过剩余AA部分的行数总和)应考虑将其提取到同一测试类的私有方法或单独的工厂类中
- Act 部分通常是一行,超过一行则表明你的生产代码对该行为的封装性不够好
- Assert 部分可以多行,但是行数过多则表明生产代码缺乏抽象,如判断两个对象是否相等,与其在测试方法中一行行断言其拥有的属性是否相等不如在对象类中增加判断对象是否相等的方法
-
拆解部分
你可能在断言后还见过拆解部分或清理部分,用于清理测试中创建的文件、数据库记录等。请注意单元测试不应该有进程外依赖,因此不会产生需要处理的副作用,这是集成测试的领域。
-
SUT(System under test)被测系统
它为你要在应用程序中调用的行为提供入口点,这个行为可以跨越多个类,也可以跨域一个方法,但它只能有一个入口:一个出发该行为的类。所以将 SUT 和其他依赖项区分开非常重要,这样你就不会花太多时间来弄清楚测试中谁是谁的问题,为此我们始终要将测试中的 SUT 命名为 sut,同时不同部分格式使用对应的注释来标明。为了方便我将上面的代码复制到此处:
// 注意:你的注释统一使用中英文就好,这里只是演示 public void test_add() { // Arrange 编排 int a = 9; int b = 10; int sum = 19; Calculator sut = new Calculator(); // Act 行动 int addSum = sut.add(a, b); // Assert 断言 assert sum == addSum; } -
尽量在测试方法中可以观察到代码的全貌
将 Arrange 部分的代码提取到测试类的构造函数中会降低测试的可读性,你不再仅通过查看测试本身就可以看到全貌,你必须检查类中的不同位置以了解测试方法的作用
-
命名风格
- 定义行为而不是实现细节,面向客户而不是程序员
sum_of_two_numbers()比sum_two_numbers_returns_sum()好 - 不要遵循严格的命名规则,复杂的行为是无法放入这样狭窄的框框内,所以要允许命名自由
- 使用下划线提高可读性,不同语言有各自的命名风格,遵循对应的风格就好
- 使用陈述句,
是就是是,不是就是不是, 不存在可能是和应该不是等
- 定义行为而不是实现细节,面向客户而不是程序员
四、编写良好的单元测试
-
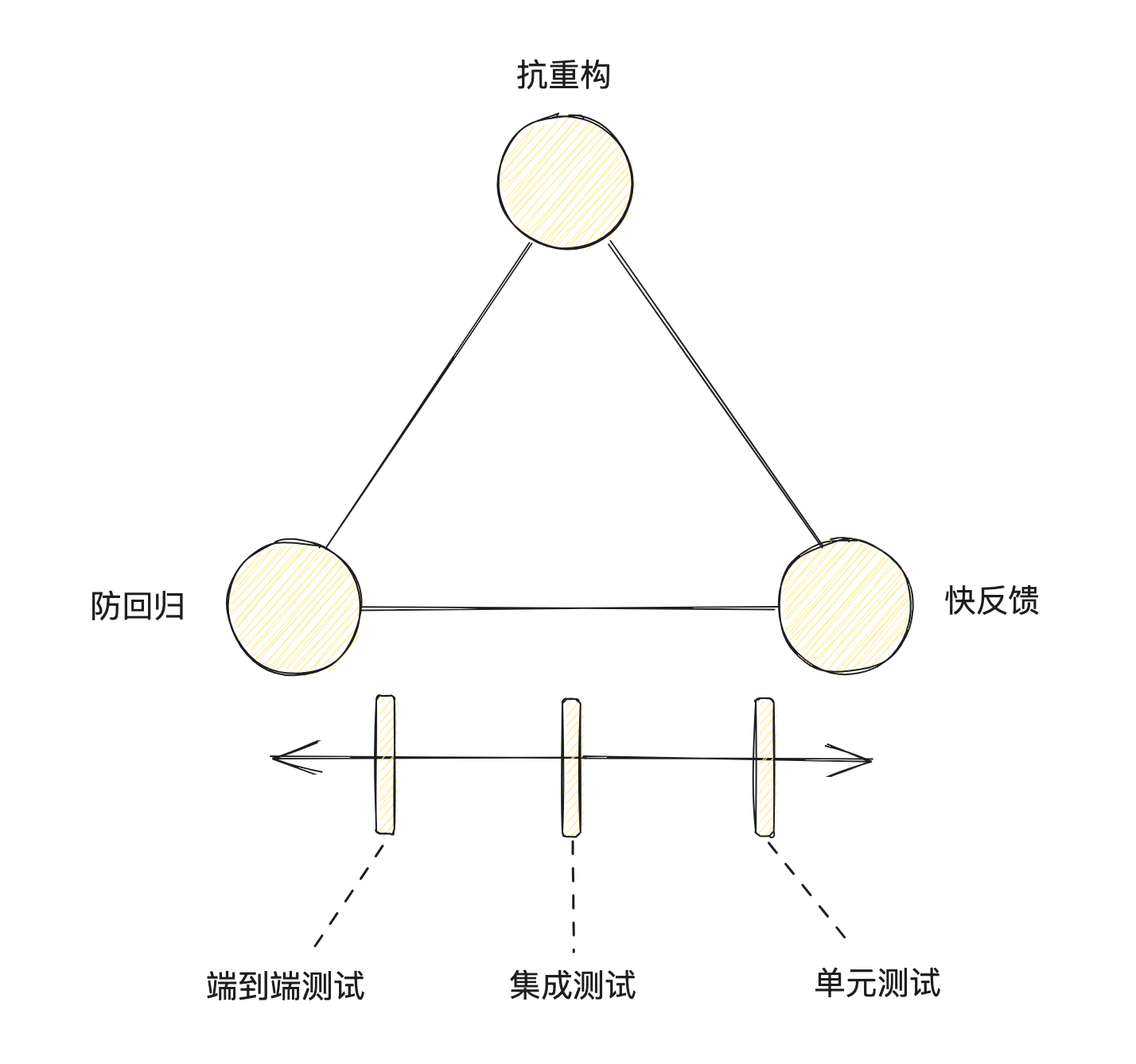
四个重要属性
- 防回归 Protection against regressions
- 抗重构 Resistance to refactoring
- 快反馈 Fast feedback
- 可维护 Maintainability
-
代码正确性和测试结果的四种可能性
- 功能正确→测试通过→结果正确
- 功能错误→测试通过→结果错误(具有良好回归保护的测试可以减少该类错误的数量)
- 功能正确→测试失败→结果错误(具有良好抵抗重构的测试可以减少该类错误的数量)
- 功能错误→测试失败→结果正确
错误类型表 功能正确 功能错误 测试通过 正确推断(真阴性) 二类错误(假阴性) 测试失败 一类错误(假阳性) 正确推断(真阳性) -
防回归(回归通俗来讲就是引入新功能后又回到了之前出问题的状态)
- 琐碎没有意义的代码不应测试,如 get set 方法
- 重点关注业务关键功能和复杂的业务逻辑
- 测试引用的三方库同样重要,你需要检查它们的行为是否符合你的预期
-
抗重构
- 要实现项目的可持续增长,测试就要满足在引入新功能或重构时而不引入回归
- 减少误报很重要,误报不仅会消磨开发人员的信心,也会减少对故障的警惕,久而久之甚至会导致开发人员忽略所有的测试失败
- 要以最终结果为目标,而不是实现细节。重构就是对实现细节的改动,如果最终结果不变,实现细节无所谓
-
快反馈
快速运行测试,快速得到反馈结果,开发人员会更愿意处理一些错误,因为这几乎没有成本。相反如果测试非常慢,每次修改完代码需要等待很长时间才能运行测试完毕,那么没有谁愿意经常运行它,而导致在错误的方向上浪费时间
-
可维护
- 理解测试的难易程度:将测试代码当作一等公民对待,它和生产代码一样重要,不要偷工减料,提高易读性,减小复杂性
- 运行测试的难易程度:如准备数据库、网络、配置等
-
测试的价值计算
测试价值=防回归x抗重构x快反馈x可维护 -
理想的测试
- 以上的表达式是惩罚计算,一旦一个指标为 0 那么该测试的价值为 0
- 防回归、抗重构、快反馈这三个指标是互斥的,不可能全部最大化
- 代码
抗重构是二极管式的,测试要么是抗重构的,要么是不抗重构的,不存在中间值。所以我们能做的就是,在满足抗重构的条件下,根据测试的目的调整防回归和块反馈的平衡
五、模拟和测试脆弱性(脆弱性对应抗重构)
-
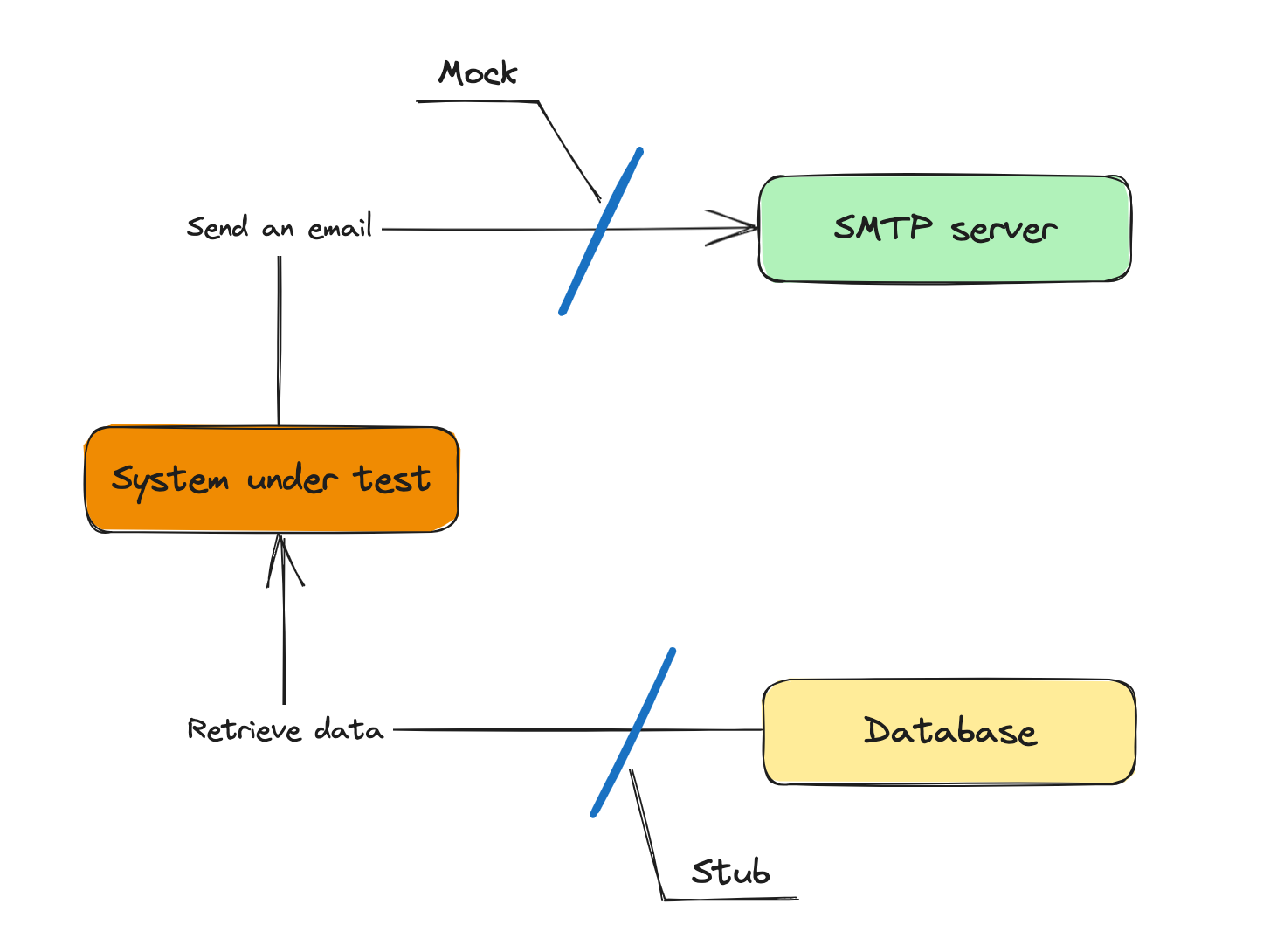
Test double 即测试替身
- mock: 模拟真实依赖项的行为,由模拟框架辅助创建的模拟对象
- spy: 和 mock 作用相同,但是是手动编写和创建的模拟对象
- stub: 复杂的、更加成熟的模拟真实依赖项,可配置为针对不同的场景返回不同的值
- dummy: 简单的、硬编码的对象,只用于满足 SUT 的方法签名,但不参与产生最后结果
- fake: 大多数的作用和 stub 相同,不同之处是其创建的原理,fake 通常是实现一个尚不存在的依赖项
-
Test double 分类
大体上可以分为两类 Mock(mock, spy) 和 Stub(stub, dummy, fake),其中
Mock 是针对输出交互且会产生副作用的测试替身, 因为 SUT 的输出是可观察的行为,所以是可以断言其交互的
Stub 是针对输入交互切不会产生副作用的测试替身,因为 SUT 的输入不是 SUT 的最终结果,也不是外部可观察的行为,而是其实现细节,所以断言其交互会产生脆弱性测试
如:
-
Command query separatio (CQS) 即命令查询分离原则
- 命令是会产生副作用且不返回值的方法
- 查询是没有副作用且返回值的方法
- 副作用:改变对象状态、更该数据库、修改系统文件等
- 实际编码中严格遵循该原则是不可能的,但尽量遵循该原则总是好的
- Mock 一般是命令,Stub 一般是查询
-
六边形架构
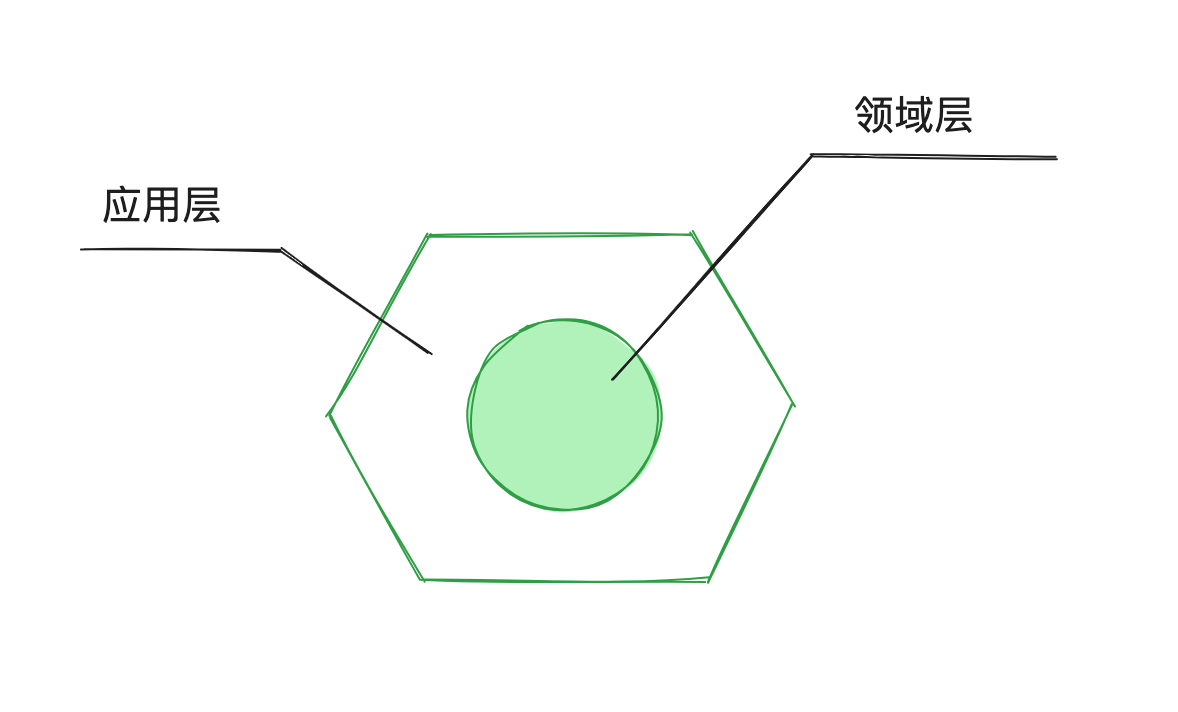
领域层位于六边形中心,它包含业务逻辑,构建应用程序的基本功能
应用层位于领域层之上,协调该层与外部世界之间的通信。如果您的应用程序是一个RESTful API,则对该 API 的所有请求都会首先到达应用程序服务层。该层然后协调域类和进程外依赖项之间的工作。
由此我们的系统自然而然类似下图

好,从这里我们可以容易看出有两种通信方式系统内通信和系统间通信
系统内通信属于实现细节,所以在该部分使用模拟会导致脆弱性
系统间通信是可观察的行为,应该在此使用模拟
注意如果数据库是不可观察的,只有该应用可以访问那么和数据库的通信是属于系统内通信
六、单元测试的风格
-
基于输出的风格
只验证一个行为的最终结果或者一个方法的返回值,这也是我们所提倡的,该风格也叫做函数式风格
-
基于状态的风格
这里的状态可以是 SUT 本身状态,也可以是其依赖项状态,在 SUT 执行后去断言状态的改变是否正确
-
基于通信的风格
即使用模拟的方式验证 SUT 与其协作者之间的通信
-
三种风格的比较
基于输出 基于状态 基于通信 抗重构成本 低 中 中 可维护成本 低 中 高 三种风格都和快反馈和防回归无关
-
函数式架构
- 函数式编程的目标是把业务逻辑和副作用分离
- 一个函数式的方法/功能没有任何隐藏输入和输出,这使得非常容易测试
- 函数式架构将副作用推到业务边缘以实现这种分离,和六边形架构相似,核心层做出决定,将决定传到外壳(业务边缘)来处理产生的副作用
七、重构有价值的单元测试
-
从两个维度观察代码
- 复杂性或领域意义
- 协作者数量
-
两个维度的组合产生四种类型的代码
- 领域模型和算法
- 琐碎的代码
- 控制器
- 过于复杂的代码
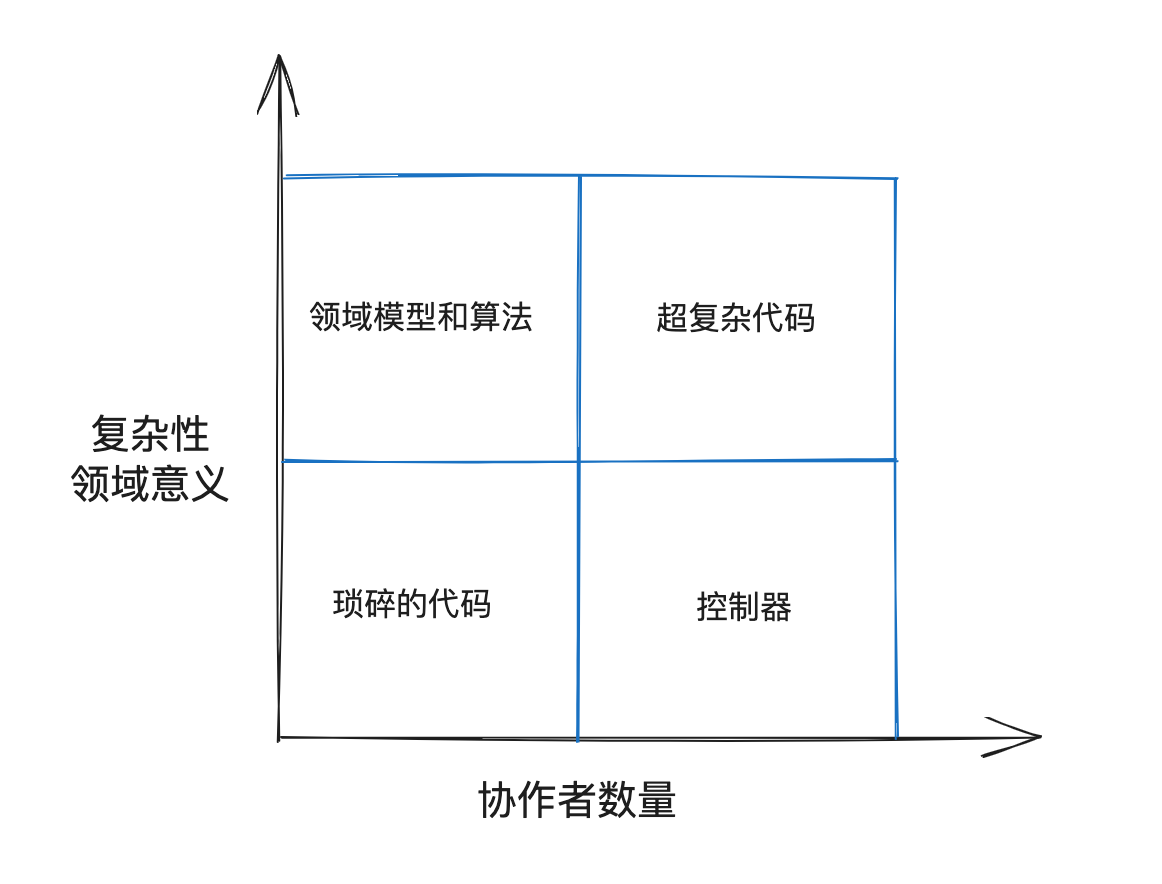
-
有价值的测试
- 领域模型和算法象限的代码最值得测试,回报高、成本低
- 琐碎的代码不值得测试
- 控制器应该在集成测试中搞
- 超复杂的代码应该被重构成领域模型和算法或控制器
-
拆分超复杂代码的考量:代码的宽度和深度
你的代码可以很深(复杂或重要)或很宽(与许多合作者一起工作),但绝不能两者兼而有之
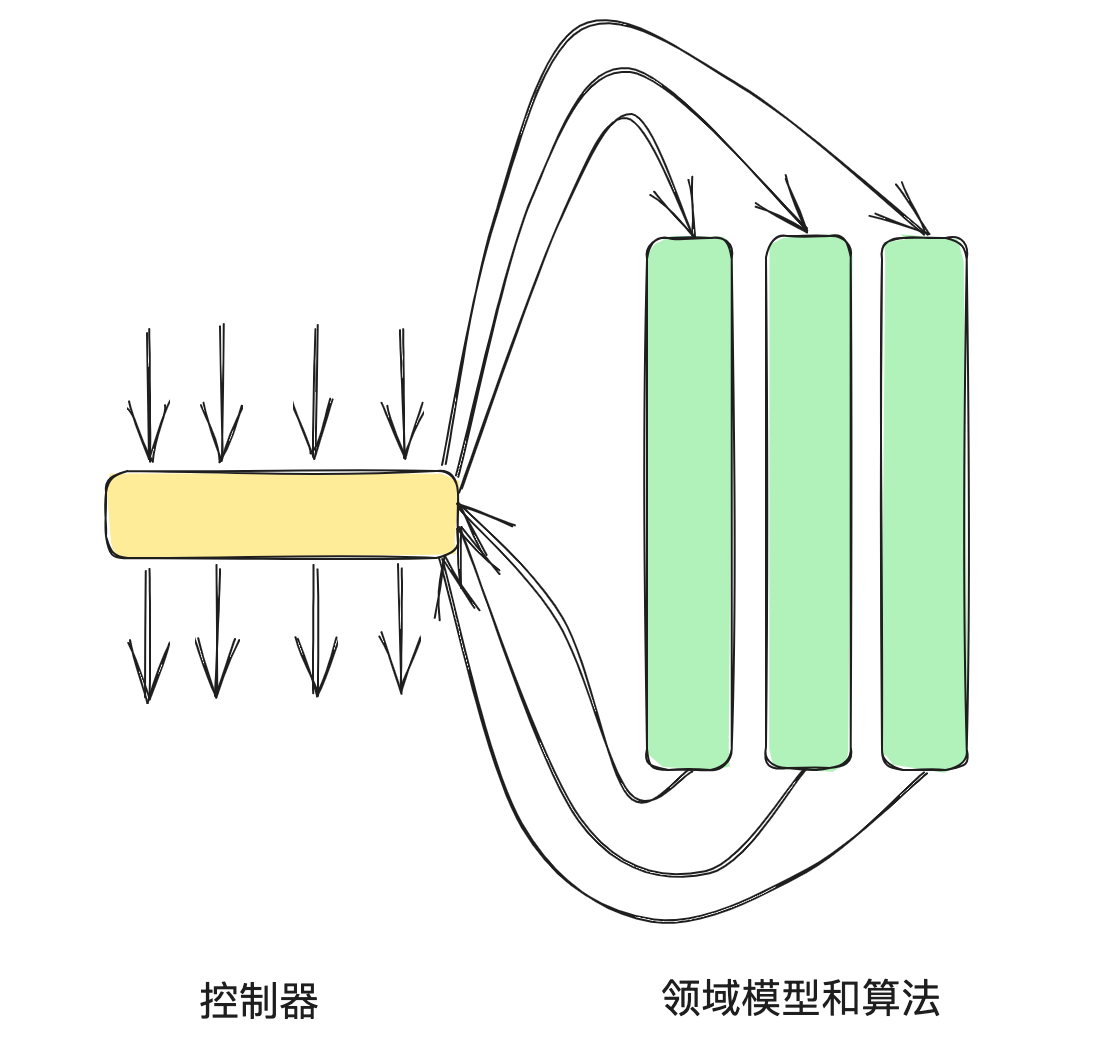
-
拆分超复杂代码的考量: 三个属性
- 领域模型可测试性
- 控制器的简单性
- 性能
同样最多满足其中两个属性
八、集成测试
-
凡是不满足单元测试任一定义的都是集成测试,即任何不适单元测试的测试
-
集成测试涵盖控制器,单元测试涵盖领域模型和算法
-
进程外依赖
- 托管依赖:只与你的应用交互,对外部世界是不可见的
- 非托管依赖:你无法完全控制的进程外依赖
对于托管依赖我们使用真正的实例,对于非托管依赖我们使用模拟
-
如果你的数据库在项目中属于托管依赖,而由于无法控制的原因无法使用数据库,那么就不要编写该部分的测试,专注于领域模型的单元测试就好
-
减少代码层数,尽量使用尽可能少的间接层。在大多数后端系统中,可以只使用其中的三个:领域模型、应用程序服务层(控制器)和基础设施层。基础设施层通常包含不属于领域模型的算法,以及允许访问进程外依赖项的代码
-
消除代码中的循环依赖
-
关于日志
- 支持日志是为支持人员和系统管理员准备的,它是应用程序可观察行为的一部分
- 支持日志记录是一项业务需求,因此请在你的代码库中明确反映该需求
- 将支持日志记录视为与进程外依赖项一起使用的任何其他功能
- 诊断日志记录有助于开发人员了解应用程序内部发生的事情,它是一个实现细节
- 不需要测试诊断日志
- 诊断日志尽量少,对于代码来说是一种噪声
九、最佳实践
- 仅将模拟应用非托管依赖项
- 在系统最比边缘验证与这些依赖的交互
- 仅在集成测试中使用模拟
- 仅模拟你拥有的类型,在提供对非托管依赖项的访问的第三方库之上编写您自己的适配器。模拟那些适配器而不是底层类型
十、数据库
- 将数据库视为常规代码,随源代码一样在 git 仓库中维护,不应在源代码控制之外对数据库结构进行任何修改
- 参考数据是数据库的一部分,如一些预设的字典值
- 每个开发者一个单独的实例
- 使用基于迁移的方式做数据库的改动,即保留每一次的更改,部署时对目标数据库执行这些更改
- 你的测试不应该依赖于数据库的状态,即你的测试应该自行将该状态带到所需条件
- 在测试开始时清理数据库数据,这是最好的选择。它工作速度很快,不会导致不一致的行为,也不容易意外跳过清理阶段
- 避免使用内存数据库模拟
十一、反模式
- 不要贪图方便而在测试时将生产代码中的一些私有项公开化,将它们作为总体可观察行为的一部分进行间接测试,或者是你应该思考你的代码抽象是否不够
- 从黑盒角度验证代码
- 代码污染是在生产代码中添加仅用于测试的代码,这是一种反模式,因为它混合了测试代码和生产代码并增加了后者的维护成本